Encyclopédie
Published in academic literature
App Summary
App Screenshots








Detailed Description
Functionality & Mechanism
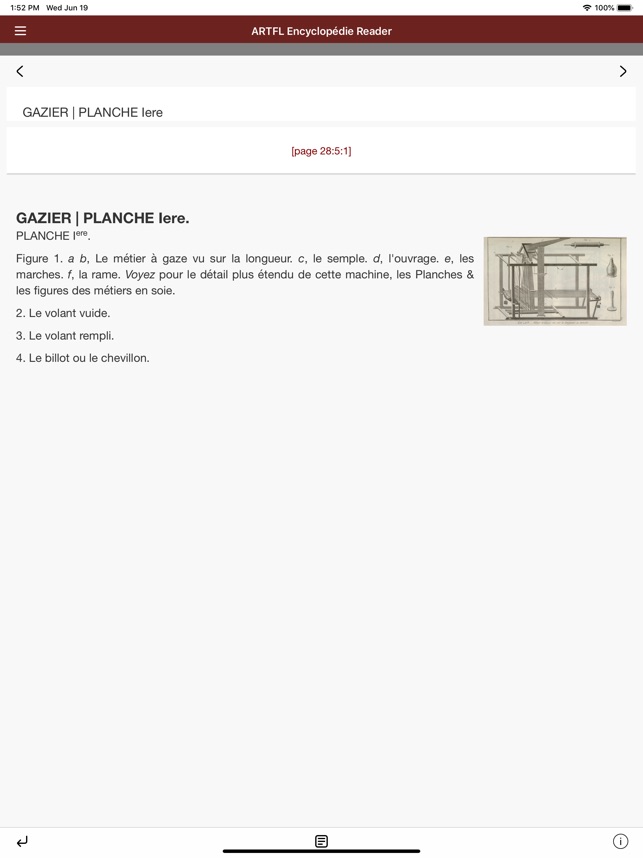
Developed by the ARTFL Project at the University of Chicago, Encyclopédie is a text search and retrieval interface for the full-text digital version of Diderot and d'Alembert's Encyclopédie. The system facilitates complex queries of the remote database, including accent-insensitive word and bibliographic searches with wildcard support. The interface presents results as either a concordance or a word frequency report. From these results, users can navigate to larger text segments, view high-resolution page and plate images, and bookmark passages.
Evidence & Research Context
- The app provides a scholarly interface to the ARTFL Project's digital edition of the Encyclopédie, a canonical 18th-century reference work comprising 74,000 articles from over 130 contributors.
- The underlying digital resource has been leveraged in computational humanities research to analyze the text's complex discursive and intellectual structures.
- Associated research utilizes Latent Dirichlet Allocation (topic modeling) to identify inter-disciplinary discourses that extend beyond the work's original classification scheme, revealing new scholarly insights.
- This application demonstrates how digital access facilitates novel methods of inquiry into historical primary sources, enabling analyses not possible with print editions.
Intended Use & Scope
This application is designed as a primary source research tool for scholars, educators, and students in history, literature, and digital humanities. Its scope is to enable deep textual analysis and content exploration of the Encyclopédie. The system is a dedicated portal to this single historical work and does not function as a general-purpose historical database or secondary reference tool.
Studies & Publications
Peer-reviewed research associated with this app.
Discourses and Disciplines in the Enlightenment: Topic Modeling the French Encyclopédie
Roe et al. (2015) · Frontiers in Digital Humanities
Referenced in academic literature; no direct evaluation of the appRe-Engineering a War-Machine: ARTFL's Encyclopedie
Andreev et al. (1999) · Literary and Linguistic Computing
Describes the research-driven development of this appApp Information
Developer
University of ChicagoCategory
Evidence Profile
Published in academic literature
Platforms
Updated
Sep 2024
© 2025 University of Chicago
Tags
Developer Links
Privacy PolicyEncyclopédie
Free